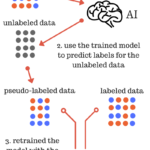
The foundation of every machine learning project is data – the one thing you cannot do without. In this post, I will show how a simple semi-supervised learning method called pseudo-labeling that can increase the performance of your favorite machine learning models by utilizing unlabeled data. Pseudo-labeling To train a machine learning model with supervised learning, the data has to be labeled. Does that meanContinue reading… Pseudo-labeling a simple semi-supervised learning method
Tag: Kaggle
SimHash for question deduplication

During the past few weeks, I have been trying to squeeze more performance out of the model for the Quora Question Pairs competition challenge on Kaggle. The goal of the competition is to detect semantically identical questions. So far, it seems that feature engineering is the way to go. I have tried most of the features that people have posted on the forum and have been researchingContinue reading… SimHash for question deduplication
Feature importance and why it’s important
I have been doing Kaggle’s Quora Question Pairs competition for about a month now, and by reading the discussions on the forums, I’ve noticed a recurring topic that I’d like to address. People seem to be struggling with getting the performance of their models past a certain point. The usual approach is to use XGBoost, ensembles and stacking. While those can generally give good results, I’dContinue reading… Feature importance and why it’s important