The foundation of every machine learning project is data – the one thing you cannot do without. In this post, I will show how a simple semi-supervised learning method called pseudo-labeling that can increase the performance of your favorite machine learning models by utilizing unlabeled data.
Pseudo-labeling
To train a machine learning model with supervised learning, the data has to be labeled. Does that mean that unlabeled data is useless for supervised tasks like classification and regression? Certainly not! Aside from using the extra data for analytic purposes, we can even use it to help train our model with semi-supervised learning – combining both unlabeled and labeled data for model training.
The main idea is simple. First, train the model on labeled data, then use the trained model to predict labels on the unlabeled data, thus creating pseudo-labels. Further, combine the labeled data and the newly pseudo-labeled data in a new dataset that is used to train the data.
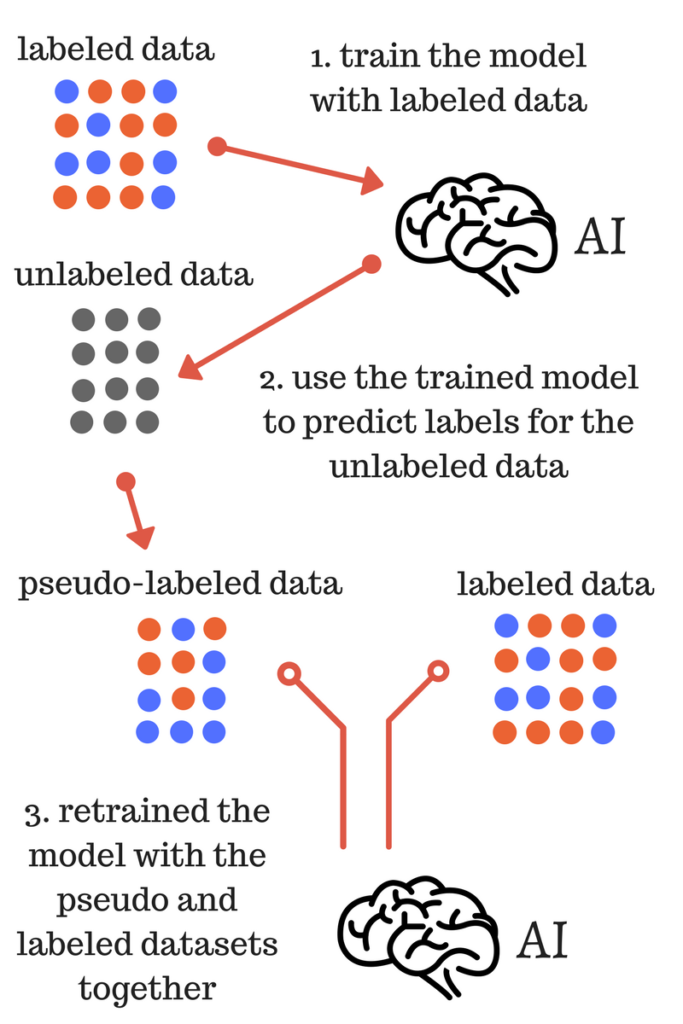
I was inspired to try this method when it was mentioned in fast.ai MOOC (original paper). Although this method was mentioned in the context of deep learning (online algorithms), I tried it out on traditional machine learning models and got slight improvements.
Data preprocessing and exploration
In competitions, such as ones found on Kaggle, the competitor receives the training set (labeled data) and test set (unlabeled data). This can be a good place to test pseudo-labeling. The dataset we will use is from the Mercedes-Benz Greener Manufacturing competition – the goal is the predict the duration of testing a car based on its features (regression). As always, all the code with additional descriptions can be found in this notebook.
import pandas as pd
# Load the data
train = pd.read_csv('input/train.csv')
test = pd.read_csv('input/test.csv')
print(train.shape, test.shape)
# (4209, 378) (4209, 377)We can see that the training dataset is not ideal, it has a low number of data points (4209) and many features (376). To improve the dataset we should reduce the number of features and try to increase the number of data points if possible. I covered feature importance (feature reduction) in a previous blog post, this topic will be skipped as the main focus of this blog post will be on increasing the number of data points with pseudo-labeling. This dataset is good for pseudo-labeling because of the small dataset and a decent ratio of labeled to unlabeled data – 1:1.
The table below shows a subset of the whole training dataset. Features X0-X8 are categorical variables and we have to transform them into in a form that is useable by our model – numerical values.
| ID | y | X0 | X1 | X2 | X3 | X4 | X5 | X6 | X8 | X10 | … | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 130.81 | k | v | at | a | d | u | j | o | 0 | … |
| 1 | 6 | 88.53 | k | t | av | e | d | y | l | o | 0 | … |
| 2 | 7 | 76.26 | az | w | n | c | d | x | j | x | 0 | … |
This was done using scikit-learn’s LabelEncoder class.
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
features = train.columns[2:]
for column_name in features:
label_encoder = LabelEncoder()
# Get the column values
train_column_values = list(train[column_name].values)
test_column_values = list(test[column_name].values)
# Fit the label encoder
label_encoder.fit(train_column_values + test_column_values)
# Transform the feature
train[column_name] = label_encoder.transform(train_column_values)
test[column_name] = label_encoder.transform(test_column_values)The result:
| ID | y | X0 | X1 | X2 | X3 | X4 | X5 | X6 | X8 | X10 | … | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 130.81 | 37 | 23 | 20 | 0 | 3 | 27 | 9 | 14 | 0 | … |
| 1 | 6 | 88.53 | 37 | 21 | 22 | 4 | 3 | 31 | 11 | 14 | 0 | … |
| 2 | 7 | 76.26 | 24 | 24 | 38 | 2 | 3 | 30 | 9 | 23 | 0 | … |
Now, the data is ready for our machine learning model.
Implementing pseudo-labeling with Python and scikit-learn
Let us create a function that creates the “augmented training set” that consists of pseudo-labeled and labeled data. The arguments of the function are the model, training and test set information (data and features), and the parameter sample_rate. Sample_rate allows us to control the percent of pseudo-labeled data that we will mix with true labeled data. Setting sample_rate to 0.0 means that the model will use only true labeled data, while sample_rate 0.5 means that the model will use all the true labeled data and half of the pseudo-labeled data. In whichever case, the model will use all the true labeled data.
def create_augmented_train(X, y, model, test, features, target, sample_rate):
'''
Create and return the augmented_train set that consists
of pseudo-labeled and labeled data.
'''
num_of_samples = int(len(test) * sample_rate)
# Train the model and creat the pseudo-labeles
model.fit(X, y)
pseudo_labeles = model.predict(test[features])
# Add the pseudo-labeles to the test set
augmented_test = test.copy(deep=True)
augmented_test[target] = pseudo_labeles
# Take a subset of the test set with pseudo-labeles and append in onto
# the training set
sampled_test = augmented_test.sample(n=num_of_samples)
temp_train = pd.concat([X, y], axis=1)
augemented_train = pd.concat([sampled_test, temp_train])
# Shuffle the augmented dataset and return it
return shuffle(augemented_train)Also, we will need a fit method – a method that trains the model – which will take the augmented training set and train the model with it. That is another function, and the one we wrote before already takes a lot of arguments. This is a good opportunity to create a class to increase cohesion and make the code cleaner, and put the methods into that class. The class we will create will be called PseudoLabeler. It will take a scikit-learn model and train it with the augmented training set. Scikit-learn allows us to create our own regressors, but we have to follow their library standard.
from sklearn.utils import shuffle
from sklearn.base import BaseEstimator, RegressorMixin
class PseudoLabeler(BaseEstimator, RegressorMixin):
def __init__(self, model, test, features, target, sample_rate=0.2, seed=42):
self.sample_rate = sample_rate
self.seed = seed
self.model = model
self.model.seed = seed
self.test = test
self.features = features
self.target = target
def get_params(self, deep=True):
return {
"sample_rate": self.sample_rate,
"seed": self.seed,
"model": self.model,
"test": self.test,
"features": self.features,
"target": self.target
}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
def fit(self, X, y):
if self.sample_rate > 0.0:
augemented_train = self.__create_augmented_train(X, y)
self.model.fit(
augemented_train[self.features],
augemented_train[self.target]
)
else:
self.model.fit(X, y)
return self
def __create_augmented_train(self, X, y):
num_of_samples = int(len(test) * self.sample_rate)
# Train the model and creat the pseudo-labels
self.model.fit(X, y)
pseudo_labels = self.model.predict(self.test[self.features])
# Add the pseudo-labels to the test set
augmented_test = test.copy(deep=True)
augmented_test[self.target] = pseudo_labels
# Take a subset of the test set with pseudo-labels and append in onto
# the training set
sampled_test = augmented_test.sample(n=num_of_samples)
temp_train = pd.concat([X, y], axis=1)
augemented_train = pd.concat([sampled_test, temp_train])
return shuffle(augemented_train)
def predict(self, X):
return self.model.predict(X)
def get_model_name(self):
return self.model.__class__.__name__Besides the “fit” and “__create_augmented_train” methods, there are several smaller methods that are required by scikit-learn in order to use this class as a regressor (you can read more about this topic in the official documentation). Now that we have created our scikit-learn class for pseudo-labeling, let us show an example.
target = 'y'
# Preprocess the data
X_train, X_test = train[features], test[features]
y_train = train[target]
# Create the PseudoLabeler with XGBRegressor as the base regressor
model = PseudoLabeler(
XGBRegressor(nthread=1),
test,
features,
target
)
# Train the model and use it to predict
model.fit(X_train, y_train)
model.predict(X_train)In the example, the PseudoLabeler class uses XGBRegressor to do regression with pseudo-labeling. The default parameter for “sample_rate” is 0.2, meaning that the PseudoLabeler will use 2
Results
To test out the PseudoLabeler, I used XGBoost (when the competition was live I was getting the best results with XGBoost). To evaluate the model, we compare the raw XGBoost against the pseudo-labeled XGBoost. Using eight-fold cross-validation (on 4k data points, each fold got a small dataset – around 500 data points). The evaluation metric is R2-score, the official metric of the competition.
XGBRegressor CV-8 R2: 0.5671 (+/- 0.1596) PseudoLabeler CV-8 R2: 0.5680 (+/- 0.1568)
The PseudoLabeler has a slightly higher mean-score and lower deviation, which makes is (slightly) superior to the raw model. I made a more detailed analysis in the notebook, you can see it here. The performance gain might seem very low, but keep in mind this is a Kaggle competition where every increase in score might bring you higher on the leaderboard. The complexity introduced here is not too big (~70 LOC) but the problem and the model are very simple in this example, keep this in mind when trying to use this on a more complex problem or domain.
Conclusion
Pseudo-labeling allows us to utilize unlabeled data while training machine learning models. This sounds like a powerful technique, and yes, it more often than not increases the performance of our models. However, it can be difficult to tune and to make it work properly, and even when it works, it gives only a slight performance boost. In competitions such as Kaggle, I believe that this technique can be useful, because, usually, even a slight increase in score can give you a boost on the leaderboard. Still, I would think twice before using this in a production environment as it seems to introduce additional complexity without a big increase in performance, and that might not necessarily be what you want.