Today, the volume of data is often too big for a single server – node – to process. Therefore, there was a need to develop code that runs on multiple nodes. Writing distributed systems is an endless array of problems, so people developed multiple frameworks to make our lives easier. MapReduce is a framework that allows the user to write code that is executed on multiple nodes without having to worry about fault tolerance, reliability, synchronization or availability.
Batch processing
There are a lot of use cases for a system described in the introduction, but the focus of this post will be on data processing – more specifically, batch processing. Batch processing is an automated job that does some computation, usually done as a periodical job. It runs the processing code on a set of inputs, called a batch. Usually, the job will read the batch data from a database and store the result in the same or different database.
An example of a batch processing job could be reading all the sale logs from an online shop for a single day and aggregating it into statistics for that day (number of users per country, the average spent amount, etc.). Doing this as a daily job could give insights into customer trends.
MapReduce
MapReduce is a programming model that was introduced in a white paper by Google in 2004. Today, it is implemented in various data processing and storing systems (Hadoop, Spark, MongoDB, …) and it is a foundational building block of most big data batch processing systems.
For MapReduce to be able to do computation on large amounts of data, it has to be a distributed model that executes its code on multiple nodes. This allows the computation to handle larger amounts of data by adding more machines – horizontal scaling. This is different from vertical scaling, which implies increasing the performance of a single machine.
Execution
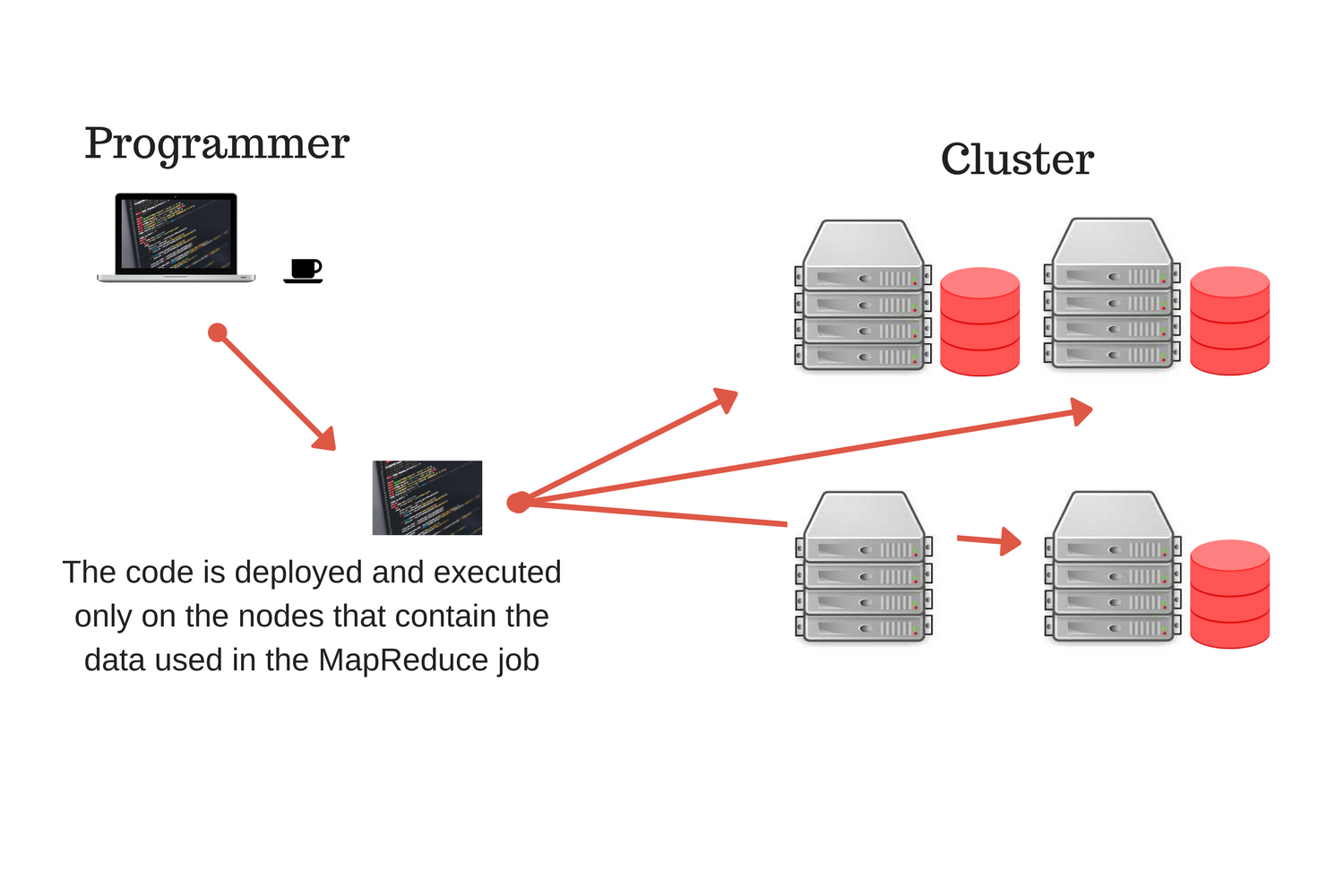
In order to decrease the duration of our distributed computation, MapReduce tries to reduce shuffling (moving) the data from one node to another by distributing the computation so that it is done on the same node where the data is stored. This way, the data stays on the same node, but the code is moved via the network. This is ideal because the code is much smaller than the data.
To run a MapReduce job, the user has to implement two functions, map and reduce, and those implemented functions are distributed to nodes that contain the data by the MapReduce framework. Each node runs (executes) the given functions on the data it has in order the minimize network traffic (shuffling data).
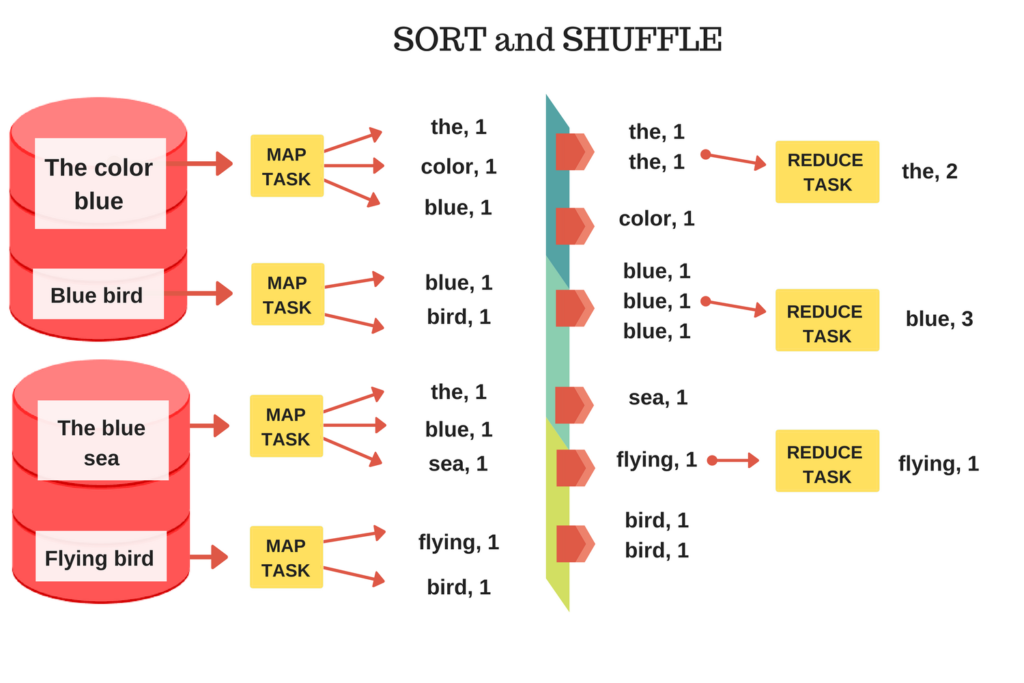
The computation performance of MapReduce comes at the cost of its expressivity. When writing a MapReduce job we have to follow the strict interface (return and input data structure) of the map and the reduce functions. The map phase generates key-value data pairs from the input data (partitions), which are then grouped by key and used in the reduce phase by the reduce task. Everything except the interface of the functions is programmable by the user.
Map
Hadoop, along with its many other features, had the first open-source implementation of MapReduce. It also has its own distributed file storage called HDFS. In Hadoop, the typical input into a MapReduce job is a directory in HDFS. In order to increase parallelization, each directory is made up of smaller units called partitions and each partition can be processed separately by a map task (the process that executes the map function). This is hidden from the user, but it is important to be aware of it because the number of partitions can affect the speed of execution.

The map task (mapper) is called once for every input partition and its job is to extract key-value pairs from the input partition. The mapper can generate any number of key-value pairs from a single input (including zero, see the figure above). The user only needs to define the code inside the mapper. Below, we see an example of a simple mapper that takes the input partition and outputs each word as a key with value 1.
# Map function, is applied on a partition
def mapper(key, value):
# Split the text into words and yield word,1 as a pair
for word in value.split():
normalized_word = world.lower()
yield normalized_word, 1
Reduce
The MapReduce framework collects all the key-value pairs produced by the mappers, arranges them into groups with the same key and applies the reduce function. All the grouped values entering the reducers are sorted by the framework. The reducer can produce output files which can serve as input into another MapReduce job, thus enabling multiple MapReduce jobs to chain into a more complex data processing pipeline.
# Reduce function, applied to a group of values with the same key
def reducer(key, values):
# Sum all the values with the same key
result = sum(values)
return resultThe mapper yielded key-value pairs with the word as the key and the number 1 as the value. The reducer can be called on all the values with the same key (word), to create a distributed word counting pipeline. In the image below, we see that not every sorted group has a reduce task. This happens because the user needs to define the number of reducers, which is 3 in our case. After a reducer is done with its task, it takes another group if there is one that was not processed.
Practical example
In order for this post to not be only dry words and images, I have added these examples to a lightweight MapReduce in Python that you can run easily run on your local machine. If you want to try this, download the code for the Python MapReduce from GitHub. The example code is in the usual place – DataWhatNow GitHub repo. The map and reduce functions are same as the ones above (word counting). The input is the first paragraph of Introduction to web scraping with Python split into partitions (defined manually by me).
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import mincemeat
partitions = [
'Data is the core of predictive modeling, visualization, and analytics.',
'Unfortunately, the needed data is not always readily available to the user,',
'it is most often unstructured. The biggest source of data is the Internet, and',
'with programming, we can extract and process the data found on the Internet for',
'our use – this is called web scraping.',
'Web scraping allows us to extract data from websites and to do what we please with it.',
'In this post, I will show you how to scrape a website with only a few of lines of code in Python.',
'All the code used in this post can be found in my GitHub notebook.'
]
# The data source can be any dictionary-like object
datasource = dict(enumerate(partitions))
def mapper(key, value):
for word in value.split():
normalized_word = word.lower()
yield normalized_word, 1
def reducer(key, values):
result = sum(values)
return result
s = mincemeat.Server()
s.datasource = datasource
s.mapfn = mapper
s.reducefn = reducer
results = s.run_server(password="datawhatnow")
print(results)
# Output
{'and': 4, 'predictive': 1, 'all': 1, 'code': 2, 'often': 1, 'show': 1, 'process': 1, 'allows': 1, 'is': 5, 'it': 1, 'not': 1, 'python.': 1, 'us': 1, 'modeling,': 1, 'in': 4, 'our': 1, 'user,': 1, 'extract': 2, 'unfortunately,': 1, 'readily': 1, 'available': 1, 'web': 2, 'use': 1, 'from': 1, 'i': 1, 'visualization,': 1, 'needed': 1, 'data': 5, 'please': 1, 'scrape': 1, 'website': 1, 'few': 1, 'only': 1, 'post,': 1, 'unstructured.': 1, 'biggest': 1, 'you': 1, 'it.': 1, 'do': 1, 'we': 2, 'used': 1, 'scraping.': 1, 'to': 4, 'post': 1, 'internet': 1, 'what': 1, 'how': 1, 'most': 1, 'analytics.': 1, 'programming,': 1, 'internet,': 1, 'core': 1, 'with': 3, 'source': 1, 'a': 2, 'on': 1, '\xe2\x80\x93': 1, 'github': 1, 'for': 1, 'always': 1, 'be': 1, 'scraping': 1, 'lines': 1, 'websites': 1, 'will': 1, 'this': 3, 'can': 2, 'notebook.': 1, 'of': 4, 'found': 2, 'the': 8, 'my': 1, 'called': 1}In order to run the Python MapReduce server and the example above, run the following inside your bash terminal:
# Run the command python2 example.py # In another window run python2 mincemeat.py -p datawhatnow localhost
If you are still having problems with running the example above, try following the official documentation on GitHub.
Congrats, you just created a MapReduce word counting pipeline. Even if this does not sound impressive, the flexibility of MapReduce allows the user to do more complex data processing such as table joins, page rank, sorting and anything you can code inside the limitations of the framework.
Conclusion
MapReduce is a programming model that allows the user to write batch processing jobs with a small amount of code. It is flexible in the sense that you, the user, can write code to modify the behavior, but making complex data processing pipelines becomes cumbersome because every MapReduce job has to be managed and scheduled on its own. The intermediate output of map tasks is written to a file which allows the framework to recover easily if a node has a failure. This stability comes at a cost of performance, as the data could have been forwarded to reduce tasks with a small buffer instead, creating a stream.
Keep in mind that this was a practical example of getting familiar with the MapReduce framework. Today, some databases and data processing systems allow the user to do computation over multiple machines without having to write the map and reduce functions. These systems offer higher-level libraries that allow the user to define the logic using SQL, Python, Scala, etc. The system translates the code written by the user into one or more MapReduce jobs, so the user does not have to write the actual map and reduce functions. This allows the users already familiar with those languages to utilize the power of the MapReduce framework with ease, using familiar tools.
Knowing the inner workings for MapReduce might allow you to write more efficient code. Also, you might be excited to learn more about the inner workings of the systems you use.