During the past few weeks, I have been trying to squeeze more performance out of the model for the Quora Question Pairs competition challenge on Kaggle. The goal of the competition is to detect semantically identical questions. So far, it seems that feature engineering is the way to go. I have tried most of the features that people have posted on the forum and have been researching new features for some time now. I found an interesting feature that I haven’t seen being mentioned before – SimHash. It is a technique for quick detection of duplicate texts. I have tried it out and now I will show the results of my research.
SimHash
All code mentioned in this post can be found on my GitHub notebook. If you are interested in a more detailed look at the data, I have done data exploration on the dataset of this problem in a previous post.
from simhash import Simhash
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
def tokenize(sequence):
words = word_tokenize(sequence)
filtered_words = [word for word in words if word not in stopwords.words('english')]
return filtered_words
q1 = "How can I be a good geologist?"
q2 = "What should I do to be a great geologist?"
print('Tokenize simhash:', Simhash(tokenize(q1)).distance(Simhash(tokenize(q2))))
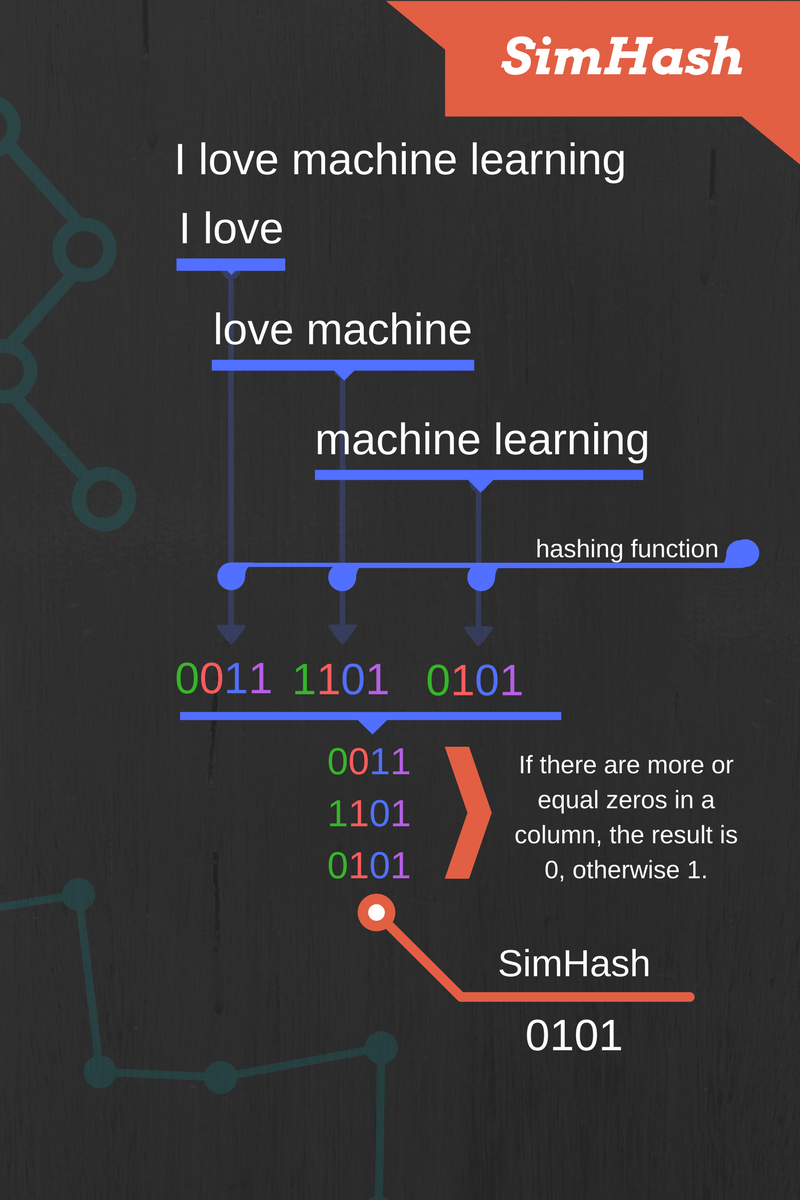
# Tokenize simhash: 20SimHash is a hashing function and its property is that, the more similar the text inputs are, the smaller the Hamming distance of their hashes is (Hamming distance – the number of positions at which the corresponding symbols are different). The algorithm works by splitting the text into chunks and hashing each chunk with a hashing function of your choice. Each hashed chunk is represented as a binary vector and the bit values are transformed into +1 or -1 depending on whether the bit value is 1 or 0. To get the SimHash, we add up all the bit vectors bit-wise. Finally, the resulting bits are set to 0 if the sum is negative, otherwise to 1.
Features
SimHash gives us a lot of creativity in building features as it requires the input text to be split into chunks before it is computed. I have explored three ways of building features: words, word n-grams and character n-grams. The code below shows a subset of functions I used to create the features. Just for the sake of clarity, I didn’t copy all 5 functions (they are in the notebook).
def caluclate_simhash_distance(sequence1, sequence2):
return Simhash(sequence1).distance(Simhash(sequence2))
def get_word_distance(questions):
q1, q2 = questions.split('_split_tag_')
q1, q2 = tokenize(q1), tokenize(q2)
return caluclate_simhash_distance(q1, q2)
def get_word_2gram_distance(questions):
q1, q2 = questions.split('_split_tag_')
q1, q2 = get_word_ngrams(q1, 2), get_word_ngrams(q2, 2)
return caluclate_simhash_distance(q1, q2)
def get_char_3gram_distance(questions):
q1, q2 = questions.split('_split_tag_')
q1, q2 = get_character_ngrams(q1, 3), get_character_ngrams(q2, 3)
return caluclate_simhash_distance(q1, q2)N-grams are continuous sequences of n items from a given sequence. In the “word n-grams” mode, the items are words. Similarly, in the “character n-grams” mode, the items are characters. If you are familiar with bioinformatics, “character n-grams” are often called k-mers.
sequence = "Mary had a little lamb, and she really liked it."
print('Tokens:', tokenize(sequence))
# ['Mary', 'little', 'lamb', ',', 'really', 'liked', '.']
print('\nWord ngrams:', get_word_ngrams(sequence, 2))
# ['Mary little', 'little lamb', 'lamb ,', ', really', 'really liked', 'liked .']
print('\nCharacter ngrams:', get_character_ngrams(sequence, 2))
# ['Ma', 'ar', 'ry', 'y ', ' l', 'li', 'it', 'tt', 'tl', 'le', 'e ', ' l', 'la', 'am', 'mb', 'b ', ' ,', ', ', ' r', 're', 'ea', 'al', 'll', 'ly', 'y ', ' l', 'li', 'ik', 'ke', 'ed', 'd ', ' .']To generate the features, I played with 2- and 3-grams. We have to be careful because, if we pick a small n, dissimilar questions may look similar. On the other hand, using a large n could lead to similar questions looking dissimilar.
pool = Pool(processes=8) train['tokenize_distance'] = pool.map(get_word_distance, train['questions']) train['word_2gram_distance'] = pool.map(get_word_2gram_distance, train['questions']) train['char_2gram_distance'] = pool.map(get_char_2gram_distance, train['questions']) train['word_3gram_distance'] = pool.map(get_word_3gram_distance, train['questions']) train['char_3gram_distance'] = pool.map(get_char_3gram_distance, train['questions'])
Model performance
Using XGBoost with the features mentioned above and without hyperparameter tuning resulted in a logloss of 0.557 (shown in the code below). In a previous post about this same problem, I have shown that a basic model with a set of 24 manually created features and no feature selection yielded a logloss of 0.63376. This is a remarkable thing to note – using only 5 simple features created with SimHash has yielded a model with 0.557 logloss, which is much better than the basic model!
features = ['tokenize_distance', 'word_2gram_distance', 'char_2gram_distance',
'word_3gram_distance', 'char_3gram_distance']
target = 'is_duplicate'
X = train[features]
y = train[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, seed=42)
model = XGBClassifier()
model.fit(X_train, y_train)
prediction_probas = model.predict_proba(X_test)
predictions = model.predict(X_test)
print('Acc:', accuracy_score(y_test, predictions)) # 0.6809
print('LogLoss:', log_loss(y_test, prediction_probas)) # 0.5570Conclusion
Even though SimHash captures only syntax similarities, it still increased the performance of this model. SimHash is not something people normally think of using in their NLP pipelines. We come back to the issue that I keep stressing: machine learning is not a matter of reusing the same recipe every time, it is a matter of finding adequate techniques appropriate to the problem at hand and having enough imagination (ahem, and powerful hardware ;)) to get the best results.