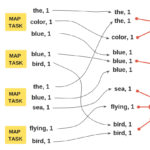
In the previous post, Introduction to batch processing – MapReduce, I introduced the MapReduce framework and gave a high-level rundown of its execution flow. Today, I will focus on the details of the execution flow, like the infamous shuffle. My goal for this post is to cover what a shuffle is, and how it can impact the performance of data pipelines. The Cost ofContinue reading… The hidden cost of shuffle – MapReduce
Tag: MapReduce
Introduction to batch processing – MapReduce
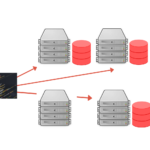
Today, the volume of data is often too big for a single server – node – to process. Therefore, there was a need to develop code that runs on multiple nodes. Writing distributed systems is an endless array of problems, so people developed multiple frameworks to make our lives easier. MapReduce is a framework that allows the user to write code that is executedContinue reading… Introduction to batch processing – MapReduce