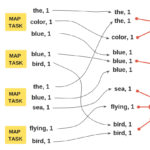
In the previous post, Introduction to batch processing – MapReduce, I introduced the MapReduce framework and gave a high-level rundown of its execution flow. Today, I will focus on the details of the execution flow, like the infamous shuffle. My goal for this post is to cover what a shuffle is, and how it can impact the performance of data pipelines. The Cost ofContinue reading… The hidden cost of shuffle – MapReduce
Things you’re probably not using in Python 3 – but should

Many people started switching their Python versions from 2 to 3 as a result of Python EOL. Unfortunately, most Python 3 I find still looks like Python 2, but with parentheses (even I am guilty of that in my code examples in previous posts – Introduction to web scraping with Python). Below, I show some examples of exciting features you can only use inContinue reading… Things you’re probably not using in Python 3 – but should
Introduction to batch processing – MapReduce
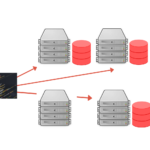
Today, the volume of data is often too big for a single server – node – to process. Therefore, there was a need to develop code that runs on multiple nodes. Writing distributed systems is an endless array of problems, so people developed multiple frameworks to make our lives easier. MapReduce is a framework that allows the user to write code that is executedContinue reading… Introduction to batch processing – MapReduce
Pseudo-labeling a simple semi-supervised learning method
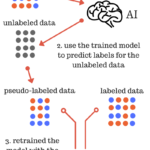
The foundation of every machine learning project is data – the one thing you cannot do without. In this post, I will show how a simple semi-supervised learning method called pseudo-labeling that can increase the performance of your favorite machine learning models by utilizing unlabeled data. Pseudo-labeling To train a machine learning model with supervised learning, the data has to be labeled. Does that meanContinue reading… Pseudo-labeling a simple semi-supervised learning method
Introduction to web scraping with Python
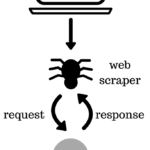
Data is the core of predictive modeling, visualization, and analytics. Unfortunately, the needed data is not always readily available to the user, it is most often unstructured. The biggest source of data is the Internet, and with programming, we can extract and process the data found on the Internet for our use – this is called web scraping. Web scraping allows us to extract dataContinue reading… Introduction to web scraping with Python
SimHash for question deduplication

During the past few weeks, I have been trying to squeeze more performance out of the model for the Quora Question Pairs competition challenge on Kaggle. The goal of the competition is to detect semantically identical questions. So far, it seems that feature engineering is the way to go. I have tried most of the features that people have posted on the forum and have been researchingContinue reading… SimHash for question deduplication
Feature importance and why it’s important
I have been doing Kaggle’s Quora Question Pairs competition for about a month now, and by reading the discussions on the forums, I’ve noticed a recurring topic that I’d like to address. People seem to be struggling with getting the performance of their models past a certain point. The usual approach is to use XGBoost, ensembles and stacking. While those can generally give good results, I’dContinue reading… Feature importance and why it’s important